AWS OpenSearch Serverless is the serverless version of AWS OpenSearch service that is aimed to significantly reduce the operational burdens of developers by eliminating the requirements for host management such as node number tuning. As a relatively new AWS service, however, it suffers from lack of supports such as detailed documentation (while it’s not ideal, but it’s very expected as developers in general do not spend time other than coding), IAM-integrated SDKs and CLI tools. In this article, I am sharing a few tips that I recently learnt from using the new service and hope it can be a useful reference.
Use Cases and Architecture
It’s important to work backwards from the use cases when designing the architecture of the system. For our use case, we have the following requirements:
- Granular Control of User Group Based: Different group of users should have different permissions on the dashboard. Some of them can only view the metrics from the dashboard(for example, product managers who want to show leadership) while others might be able to create new dashboard and analyze the data(such as data scientists).
- Allow Cross Account Lambda Ingestion: While OpenSearchServerless provides a rich set of tools for data ingestion, it’s usually more practical to leverage existing infrastructures that are already highly customized. One such tool is AWS Lambda that basically allows a the producers to use whatever logic they like to transform the data for ingestion. For our use case, the lambda exists on another different account than the serverless collection and because of current limitation of the service, the IAM role needs to be in the same account as the Collection.
The architectural requirement can thus be summarized as:
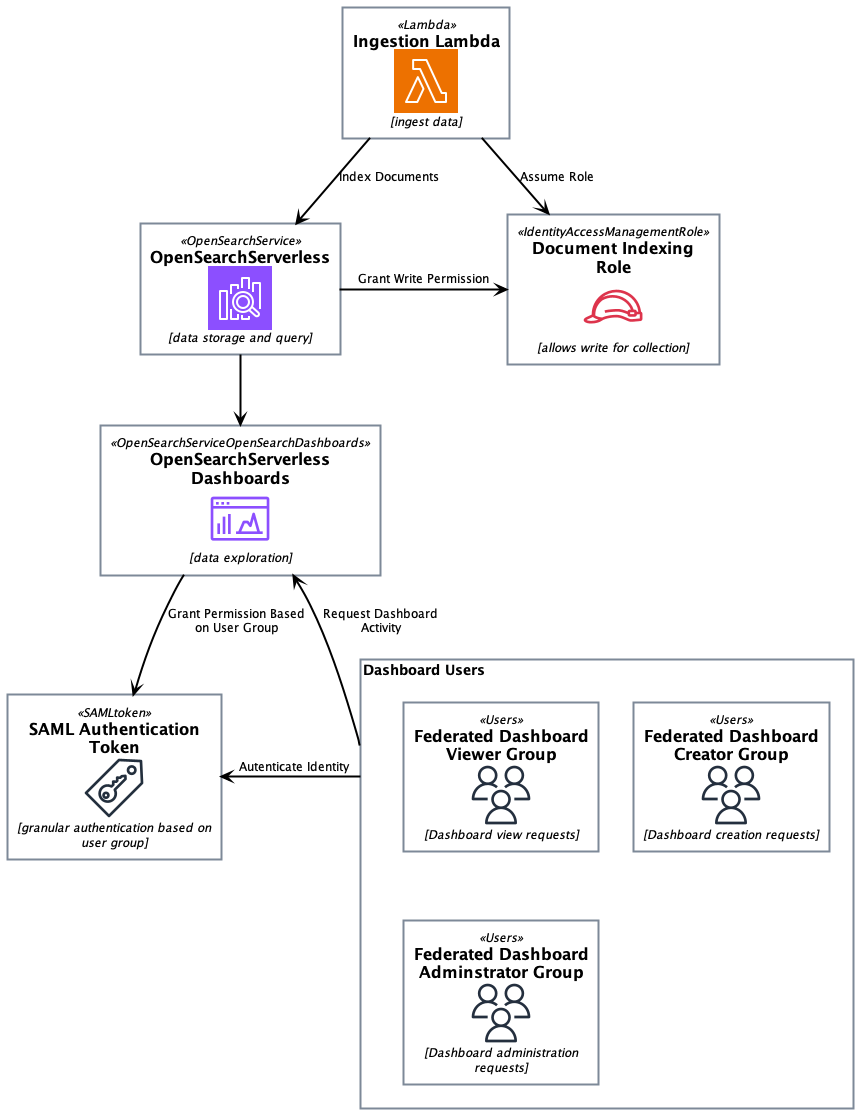
CDK Template for Collection Creation
The first “gotcha” I encountered was to spin up the service using AWS CDK. I was expecting a fairly straightforward process as I usually do with other AWS resources such as S3 and DynamoDb, but I immediately found out the following notes from the official documentation:
There are no official hand-written (L2) constructs for this service yet.
So this means that creating Collections with CDK is not as easy as creating other infrastructures. After a lot of trial and error and countless build, deploy and test, the following pitfalls are worth mentioning:
APIAccessAllis required if programmatic access is desired (which is almost always the case when the collection is a consumer from other components/services).Encryption Security Policyis required which is different than other storage services.Network Security Policyis required even with no VPC configuration is needed.IAMandSAMLentities that are used to access the data need to be in the same AWS account as the collection.
The following code snippets can be used as reference that corresponds to the architecture as outlined previously while complying the aforementioned requirements:
const samlSecurityConfig = new CfnSecurityConfig(this, 'SamlSecurityConfig', {
name: 'federate-saml-provider',
type: 'saml',
description: 'The Federate Provider that enables login to the OpenSearch Dashboard.',
samlOptions: {
sessionTimeout: 720,
metadata: samlSecurityConfigMetaData,
},
});
const apiAccessPolicy = new PolicyStatement({
actions: [
'aoss:APIAccessAll',
],
resources: [
'*',
],
effect: Effect.ALLOW,
});
const collectionWriteAccessRole = new Role(this, CollectionWriteAccessRole', {
assumedBy: ACCOUNT_PRINCIPAL,
roleName: `WriteAccessRole`,
});
collectionWriteAccessRole.addToPolicy(apiAccessPolicy);
const collectionReadAccessRole = new Role(this, 'CollectionReadAccessRole', {
assumedBy: ACCOUNT_PRINCIPAL,
roleName: `ReadAccessRole`,
});
collectionReadAccessRole.addToPolicy(apiAccessPolicy);
const cfnCollection = new CfnCollection(this, 'Collection', {
name: COLLECTION_NAME,
description: 'open search collection',
type: 'TIMESERIES', // This is a key parameter that needs to be carefully considered
});
const collectionEncryptionSecurityPolicy = new CfnSecurityPolicy(this, 'Encryption', {
description: 'Encryption security policy',
name: 'encryption',
policy: JSON.stringify({
AWSOwnedKey: true,
Rules: [
{
Resource: [`collection/${COLLECTION_NAME}`],
ResourceType: 'collection',
},
],
}),
type: 'encryption',
});
const collectionNetworkSecurityPolicy = new CfnSecurityPolicy(this, 'Network', {
description: 'Network security policy',
name: 'network',
policy: JSON.stringify([{
AllowFromPublic: true,
Rules: [
{
Resource: [`collection/${COLLECTION_NAME}`],
ResourceType: 'dashboard',
},
{
Resource: [`collection/${COLLECTION_NAME}`],
ResourceType: 'collection',
},
],
}]),
type: 'network',
});
const collectionAdminAccessPolicy = new CfnAccessPolicy(this, 'DataAdminAccess', {
description: 'Data admin access policy',
name: 'data-admin',
policy: JSON.stringify([
{
Description: 'Admin Access',
Rules: [
{
Permission: ['aoss:*'],
Resource: ['collection/collection'],
ResourceType: 'collection',
},
{
Permission: ['aoss:*'],
Resource: ['index/collection/*'],
ResourceType: 'index',
},
],
Principal: [
ADMIN_ROLE,
],
},
]),
type: 'data',
});
const collectionReadAccessPolicy = new CfnAccessPolicy(this, 'DataReadAccess', {
description: 'Data read access policy',
name: 'data-read',
policy: JSON.stringify([
{
Description: 'Readonly Dashboards Access',
Rules: [
{
ResourceType: 'collection',
Resource: [`collection/${COLLECTION_NAME}`],
Permission: ['aoss:DescribeCollectionItems'],
},
{
ResourceType: 'index',
Resource: [`index/${COLLECTION_NAME}/*`],
Permission: [
'aoss:DescribeIndex',
'aoss:ReadDocument',
],
},
],
Principal: [
SAML_PRINCIPAL,
READ_ROLE_ARN,
],
},
]),
type: 'data',
});
const collectionWriteAccessPolicy = new CfnAccessPolicy(this, 'DataWriteAccess', {
description: 'Data write access policy',
name: 'data-write',
policy: JSON.stringify([
{
Description: 'Data Write Access',
Rules: [
{
ResourceType: 'collection',
Resource: [`collection/${COLLECTION_NAME}`],
Permission: [
'aoss:DescribeCollectionItems',
'aoss:CreateCollectionItems',
'aoss:UpdateCollectionItems',
],
},
{
ResourceType: 'index',
Resource: [`index/${COLLECTION_NAME}/*`],
Permission: [
'aoss:DescribeIndex',
'aoss:UpdateIndex',
'aoss:ReadDocument',
'aoss:WriteDocument',
'aoss:CreateIndex',
],
},
],
Principal: [
collectionWriteAccessRole.roleArn,
],
},
]),
type: 'data',
});
cfnCollection.addDependency(collectionEncryptionSecurityPolicy);
cfnCollection.addDependency(collectionNetworkSecurityPolicy);
cfnCollection.addDependency(collectionAdminAccessPolicy);
cfnCollection.addDependency(collectionReadAccessPolicy);
cfnCollection.addDependency(collectionWriteAccessPolicy);
Sigv4 Authenticated Calls to Collections
As a standard AWS service, Sigv4 is required to interact with the collection endpoint. Again, there is no detailed documentation on how to do it and after some exploration, we have figured out some general approaches.
AWS CURL
The quickest way to test the service is using CLI tools because it require literally zero amount of programming (not even scripting). Unfortunately, as of today, official AWS CLI doesn’t provide data operations support (such as indexing). Nevertheless, there is awscurl for rescue. In my opinion, awscurl is the best CLI tool to for AWS service API interaction because it provides a very generic interface and has a really nice general implementation for Sigv4 authentication. With credentials setup properly (i.e. AWS IAM role/user credentials are available from the environment variables), interacting with collection can be as easy as:
awscurl --service aoss -X GET https://${collection_endpoint}/_search --region us-west-2 | jq
And we can get results back:
{
"took": 69,
"timed_out": false,
"_shards": {
"total": 0,
"successful": 0,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 1,
"hits": [
// hits data
]
}
}
Java SDK
The second big surprise for me was how rudimentary the Java SDK is especially for the authentication part. Finally, it turns out that:
- Additional configurations of
AwsSdk2Transportis required, which for most other mature AWS services have already been encapsulated in their SDKs. - The right client dependency is important. Because of historical reasons, there are few different versions of clients and the one that is proved to be working for us is
Maven-org-opensearch-client_opensearch-java.
Example of client setup:
final StsClient stsClient = StsClient.builder()
.httpClient(UrlConnectionHttpClient.builder().build())
.credentialsProvider(DefaultCredentialsProvider.create())
.region(Region.of(REGION))
.build();
final AssumeRoleRequest assumeRoleRequest = AssumeRoleRequest.builder()
.roleSessionName(AOSS_SESSION_NAME)
.roleArn(IAM_ROLE_ARN)
.build();
final StsAssumeRoleCredentialsProvider credentialsProvider = StsAssumeRoleCredentialsProvider.builder()
.stsClient(stsClient)
.refreshRequest(assumeRoleRequest)
.build();
final AwsSdk2TransportOptions transportOptions = AwsSdk2TransportOptions.builder()
.setCredentials(credentialsProvider)
.build();
final AwsSdk2Transport awsSdk2Transport = new AwsSdk2Transport(UrlConnectionHttpClient.builder().build(),
COLLECTION_ENDPOINT,
"aoss",
Region.of(REGION),
transportOptions);
return new OpenSearchClient(awsSdk2Transport);
Example of match query:
final MatchQuery matchQuery = new MatchQuery.Builder()
.field(FIELD_TO_MATCH)
.query(FieldValue.of(VALUE_TO_MATCH))
.build();
final SearchRequest searchRequest = new SearchRequest.Builder()
.query(matchQuery._toQuery())
.index(INDEX_TO_QUERY)
.build();
final SearchResponse searchResponse = this.openSearchClient
.search(searchRequest, Document.class);
Final Words
I didn’t expect this article to be this lengthy when I first planned to share my thoughts, but it turned out to be the longest article I have written so far, due to the amount of code snippets that included here. Anyway, I hope it provides some useful reference that can help someone to unblock him/herself.